
Marco Denisi




L’ultimo anno e mezzo è stato particolarmente denso dal punto di vista lavorativo. Infatti, il progetto sul quale ho lavorato maggiormente è stato oggetto di un paio di grossi cambiamenti organizzativi che hanno richiesto anche un cambio di paradigma della gestione del codice.
Oggi vorrei condividere questa mie esperienza focalizzandomi sulla branching strategy.
Git è diventato lo standard de facto per i sistemi di versionamento del codice per la sua semplicità. Infatti, i concetti critici di Git sono pochi:
Quello che rende il concetto di commit così importante è la relazione con altri commit. Questa relazione genera i concetti di history e di revision.
Un branch non è nient’altro che una referenza ad un commit. La loro creazione è un processo molto semplice, così come il loro merge. Questo può portare ad una proliferazione di branch all’interno di un repository. Ed è qui che entrano in gioco le branching strategies.
Queste strategie sono delle regole che gli sviluppatori si danno su:
Esiste una pletora di strategie diverse, ognuna con i suoi pro e contro (git flow, GitHub flow, trunk based development, …). Quello che voglio descrivere è un po' il mio viaggio tra le strategie che abbiamo adottato, e parlando di viaggi…

Ho individuato tre macro fasi che nella mia testa si sono associate automaticamente alle tre cantiche della Divina Commedia. Finito questo Canto Introduttivo, passiamo alla mia prima fase.
Nella prima fase del progetto, diversi team lavoravano su una sola codebase. Non avevamo un’ambiente di produzione, ma solo un ambiente di sviluppo per testare le integrazioni tra backend e frontend.
Il business dava i requisiti sulle nuove funzionalità che erano rilasciate in questo ambiente di sviluppo. Da qui, la strategia di branching:
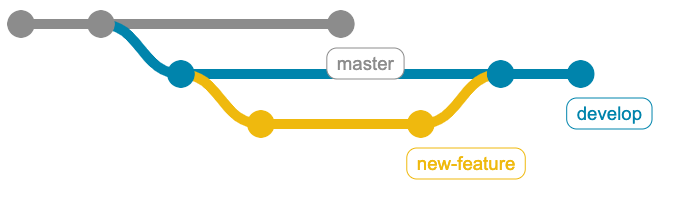
Non molto originale, ma funzionale. Difatti, l’ho associata al purgatorio: da un lato la mancanza di regole stringenti rendeva il tutto molto semplice, dall’altra ogni team/sviluppatore andava per conto suo.
Nella fase intermedia del progetto ci si è accorti di alcune limitazioni del modello precedente. La necessità di avere una visione univoca sul prodotto ha portato alla creazione di un unico team che lavorava sulla codebase.
In questa fase è avvenuto il massimo sforzo: business dava nuovi requisiti senza soluzione di continuità. Inoltre, sono stati messi in piedi più ambienti: test, stage e produzione.
Per supportare al meglio questo cambiamento abbiamo adattato anche la branching strategy, portandola molto vicino a git flow:

Paradiso? Forse no, ma ci siamo molto vicini. Regole ben definite portano a concentrarsi principalmente sullo sviluppo, soprattutto se supportati da CI e CD ben studiate (come nel nostro caso).
Nella fase finale del progetto la composizione del team non è cambiata. Quello che è cambiato è il modo con cui il business da i requisiti.
Il problema principale che abbiamo affrontato è che requisiti diversi dovevano andare in produzione con tempistiche diverse nonostante dovessero essere sviluppati contemporaneamente. Alcuni non erano nemmeno compatibili tra loro (esempio: funzionalità che devono essere attive solo per un lasso di tempo).
Il modello di branching è cambiato nuovamente ed è molto vicino al modello Release Train che Martin Fowler ha spiegato dettagliatamente qui. In due parole:
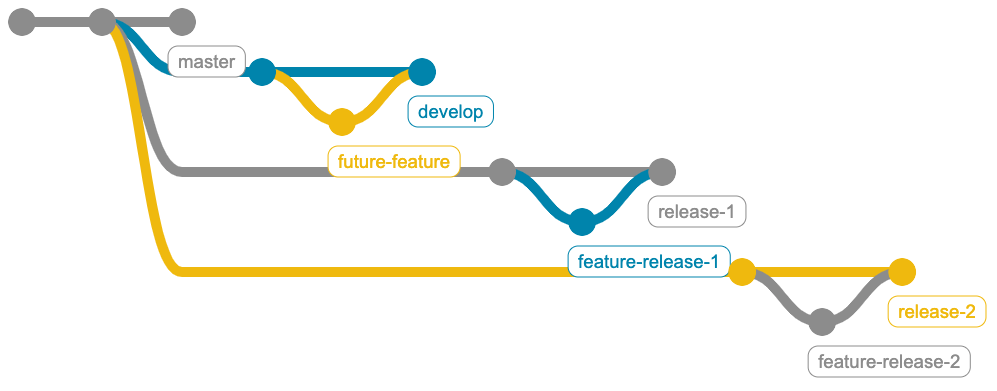
Di per se la strategia è chiara, ma le differenze da quella precedente sono molte. L’inferno sta proprio qui: cambiare così tanto il modo di lavorare porta a errori e incomprensioni all’interno del team. Ci vuole tempo perché tutti si abituino a questo nuovo flusso. Anche la CI/CD è cambiata, per non parlare dei vari ambienti.
Questa è la conclusione del mio viaggio. Probabilmente ci sarà una fase successiva nella quale la codebase verrà divisa in microservizi ed il team verrà a sua volta diviso per formare i cosiddetti feature team. Questo semplificherà enormemente i flussi e risolverà molti dei problemi che abbiamo incontrato. Ma questa è un’altra storia…

Quello che ho imparato è che le scelte del business impattano in maniera decisiva anche le questioni che potrebbero sembrare prettamente tecniche. Quindi, cambiamenti di questo tipo devono essere valutati attentamente e non devono avvenire troppo spesso. Non solo per una questione di costi ma anche per evitare dei gran mal di testa al team di sviluppo.